2019-11-01
Local Development vs. Virtual Box and Vagrant vs. Container like Docker or Kubernetes
In this post I am comparing three things: 1. local (web) development, 2. classical virtualization using Hypervisors such as Virtual Box, 3. containerization and orchestration tools such as LXC, Docker, docker-compose, docker-swarm and Kubernetes. On top, we will also talk about Puppet, Chef or Ansible and/or Vagrant for automation.
If you want to digest this as a video, feel free to watch this:
For this example I'm assuming you are building some "WebApp", that might be in Java or PHP or Ruby. This is served by a web-server like Apache or Nginx. And this WebApp uses some database to read and write data persistently, which might be MySQL or Redis. In essence, we can call these "services" which interact with each other.
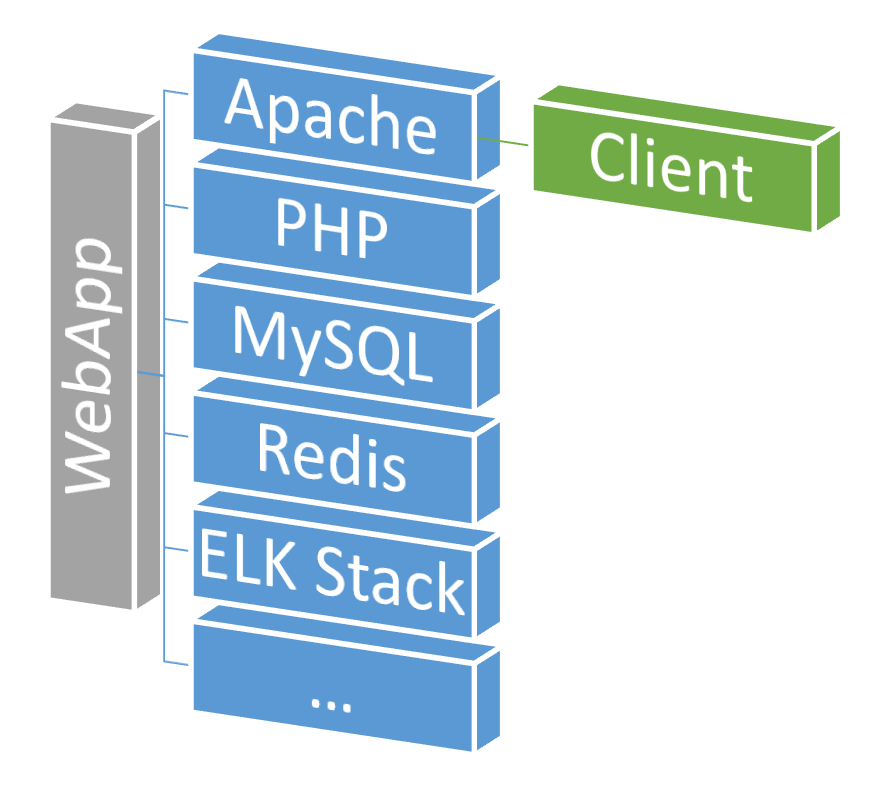 That might look like your WebApp Service Stack?
Your development workflow probably looks like this:
That might look like your WebApp Service Stack?
Your development workflow probably looks like this:
-
You develop locally, on your machine
-
You deploy the code to some server
-
The server runs the code
-
when there are updates, you repeat the steps 1-3
If you get larger, you maybe add more servers, like a testing server or staging server or demo-server. To keep things simple here, I'll skip those and focus on the main parts.
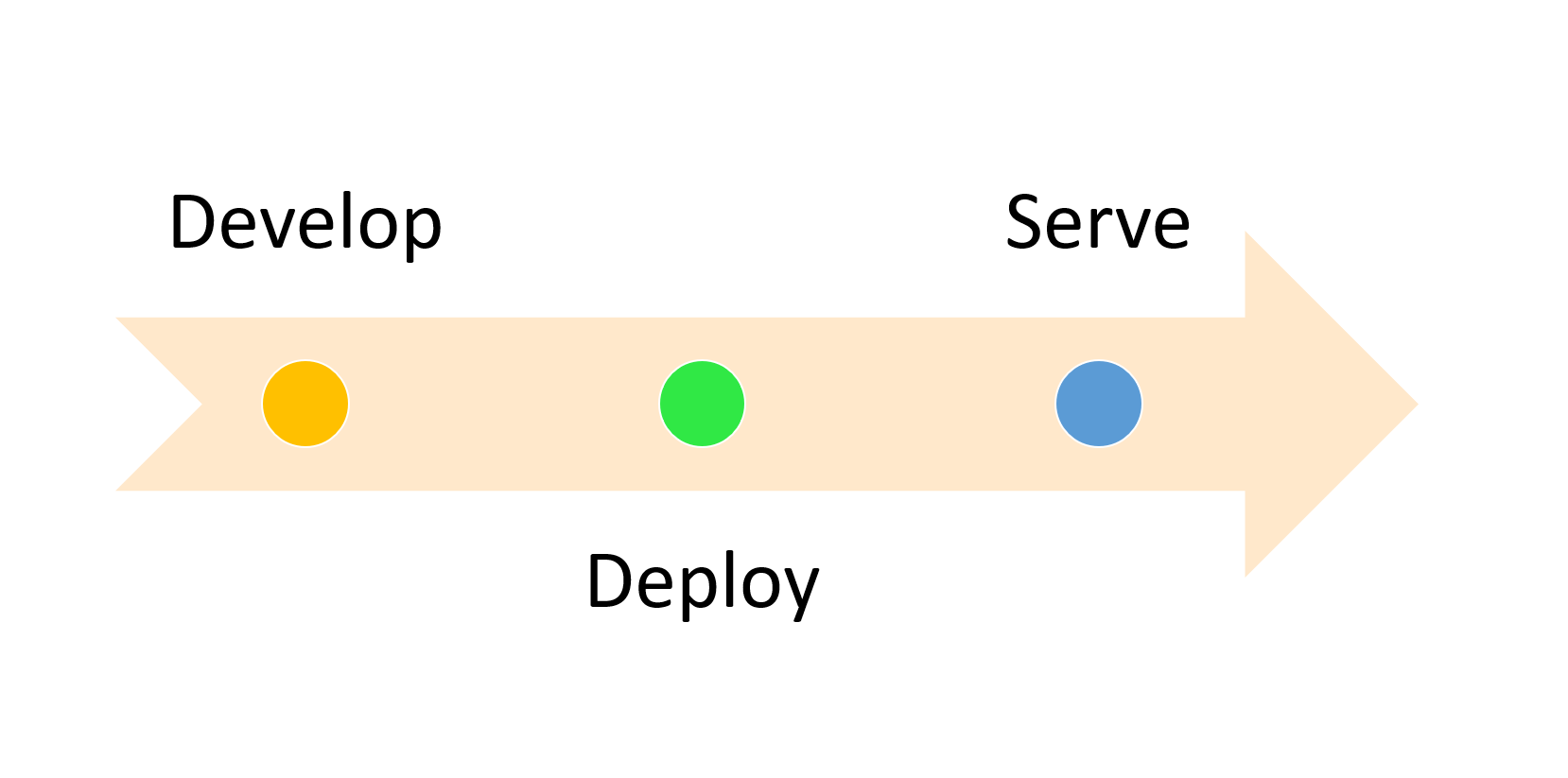 Classical Workflow for Development to Production
The workflow looks fairly straight forward, I hope. But, there is always more details to it: Your local development machine ("development environment" or "dev") has most likely a different configuration than the server ("production environment" or "prod") your code is deployed to. And, of course, in a perfect world you try to have your dev environment as similar as possible to your production environment. It's called trying to "reach dev-prod parity".
Classical Workflow for Development to Production
The workflow looks fairly straight forward, I hope. But, there is always more details to it: Your local development machine ("development environment" or "dev") has most likely a different configuration than the server ("production environment" or "prod") your code is deployed to. And, of course, in a perfect world you try to have your dev environment as similar as possible to your production environment. It's called trying to "reach dev-prod parity".
There are usually three broad categories of development environments. For these three I want to discuss the benefits and drawbacks:
- Use a local "host OS" development environment (e.g. install Apache and MySQL directly)
- Use Hypervisors and virtual machines, such as VirtualBox and maybe use Vagrant on top
- Use Containers and something like LXC or Docker or Kubernetes
 On top, you could manage all of those with tools like Ansible, Puppet or Chef. So, without further ado, let's dive into the first one.
On top, you could manage all of those with tools like Ansible, Puppet or Chef. So, without further ado, let's dive into the first one.
The *Local *Development Environment
Let's use a WebApp written in PHP and MySQL for this example, since it's so tremendously common and I have used this myself for many years.
A 2019 Stack Overflow survey showed that 45.3% of professional developers are using Windows, 29.2% use MacOS and 25.3% use Linux. I am a Windows user. That isn't very significant for the example itself, but chances are, that you are in the statistical group of Windows users as well. And it's very likely that your server runs Linux, as roughly 79% do, statistically. Your setup might look something like this:
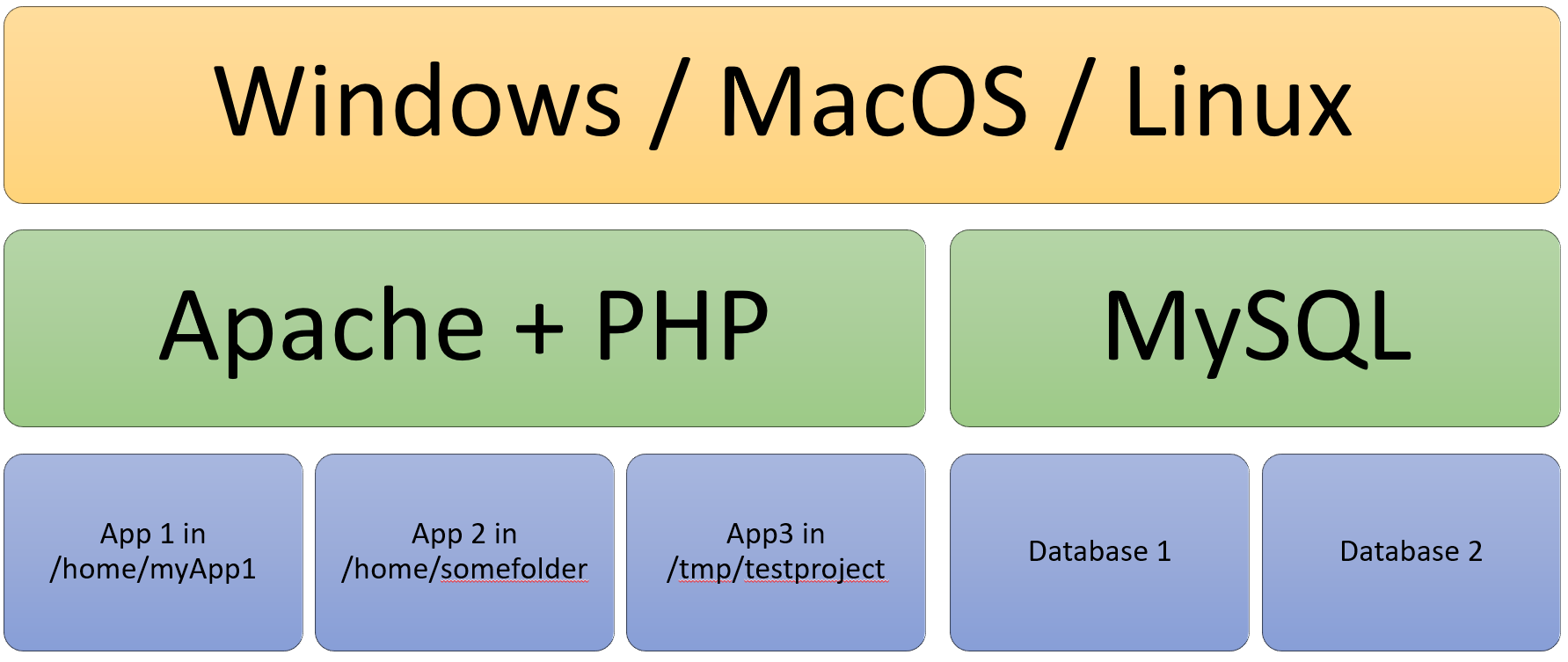 If you work in a team, then you maybe have another colleague who works on a Mac. So, all in all, it's not very uncommon that the development environment is different from developer to developer and that is then extremely different than the production environment.
If you work in a team, then you maybe have another colleague who works on a Mac. So, all in all, it's not very uncommon that the development environment is different from developer to developer and that is then extremely different than the production environment.
If you have ever worked with Apache and PHP then you probably know that there are pre-configured packages to download and install. Those are called XAMPP. X = Linux|MacOs|Windows, A = Apache, M = MariaDB or MySQL, P = PHP, P = Perl. It comes with an installer and pre-configured, turn key to start with. This works very well to start prototyping. Until you hit a few platform specific problems.
I am talking about PHP here, because there are a lot of web-developers out there using PHP. But the problems are not uncommon in really any language you run, so, consider this a universal problem.
Problems With Local Development
Here are real-life problems you would be facing as a developer between Unix and Windows.
- Unix uses the forward slash "/" and Windows the backwards slash "". This alone caused many applications to break, or at least the need to find workarounds.
- And there is the file name case sensitivity. If you store data in a MySQL Database, then the tables are stored in actual files on the system. Unix-like file systems are case-sensitive while Windows is not. That means your Database table names on windows all become lower-case, no matter what.
- File encoding and file delimiter: On Windows, by default, your source code is most likely not in UTF-8 by default, and it has the \r\n line endings. While on Linux you just have the \n endings. There is, of course, a setting in every decent IDE, and on top a setting in Git for commits to auto-translate those. But if you ever had a new hire who forgot to set this, you know the dilemma.
- Also, the temporary directory is in a different place between Linux and Windows
- The way file-system permissions are implemented is, of course, very different on Linux and Windows
- And then, finally, things that work under one version of Windows may fail under another version of Windows.
There are tons of other problems you maybe can relate to some degree, I don't even mention here. But not everything is outright bad with local development.
Benefits of Local Development
First, let me say the performance is great. There is almost no complexity or hidden layers to work through. Everything runs native on your system, so, no emulators, no mappings.
It's very clear what happens locally, as there are no other layers (like Hypervisors, guest OSes, or anything else) between your file and the Apache web-server. You update a file, done. Nothing to "make", nothing to publish, nothing to generate, check in, release, copy, mount, map or whatnot. It's super easy and super simple.
Still, as soon as your project hits a certain size it becomes increasingly inconvenient. It feels like moving USB Sticks with code around while you could instead use tools like GitHub. So, let's see if we can do better than this.
The next logical step is to move everything to the exact same underlying system or platform as your server on all development environments across all employees. So, if your server runs Linux then it's desirable to use Linux for your development environment as well, right? But not everyone who uses Windows wants to delete it and install Ubuntu instead.
There are ways to do this without re-installing another operating system. The majority of developers would probably chose to use a virtual machine, since it's so easy to understand.
Virtual Machines and Vagrant
A virtual machine is basically a full operating system, that runs *within *your local operating system, but totally separate from that. The local operating system is often called the "host OS" and the one running inside the host OS is called the "guest OS".
You have probably seen graphics like this one, or similar to this one:
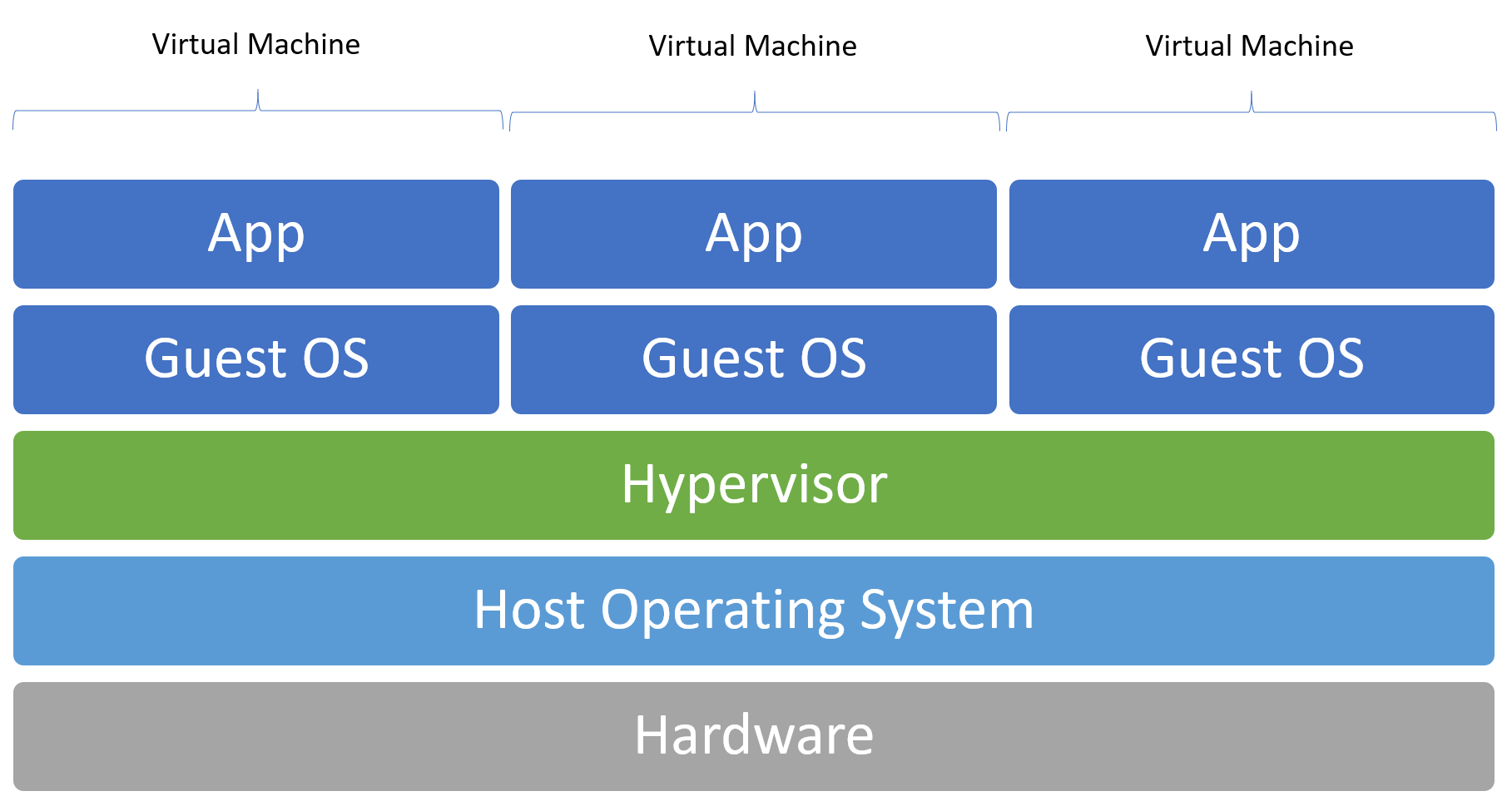 Typical Layout of Virtual Machine on Hypervisor on Host Operating System
If you want to run a virtual machine you need a so called Hypervisor. If we stick with our Windows example, you would install something like Virtual Box or VMWare. This would be then be called a "Layer 2 Hypervisor", because you are installing a Hypervisor inside an existing Operating System. If the Hypervisor runs on bare metal, without another operating system like Windows in between then it's a Layer 1 Hypervisor. That's just for your information and not important at all here.
Typical Layout of Virtual Machine on Hypervisor on Host Operating System
If you want to run a virtual machine you need a so called Hypervisor. If we stick with our Windows example, you would install something like Virtual Box or VMWare. This would be then be called a "Layer 2 Hypervisor", because you are installing a Hypervisor inside an existing Operating System. If the Hypervisor runs on bare metal, without another operating system like Windows in between then it's a Layer 1 Hypervisor. That's just for your information and not important at all here.
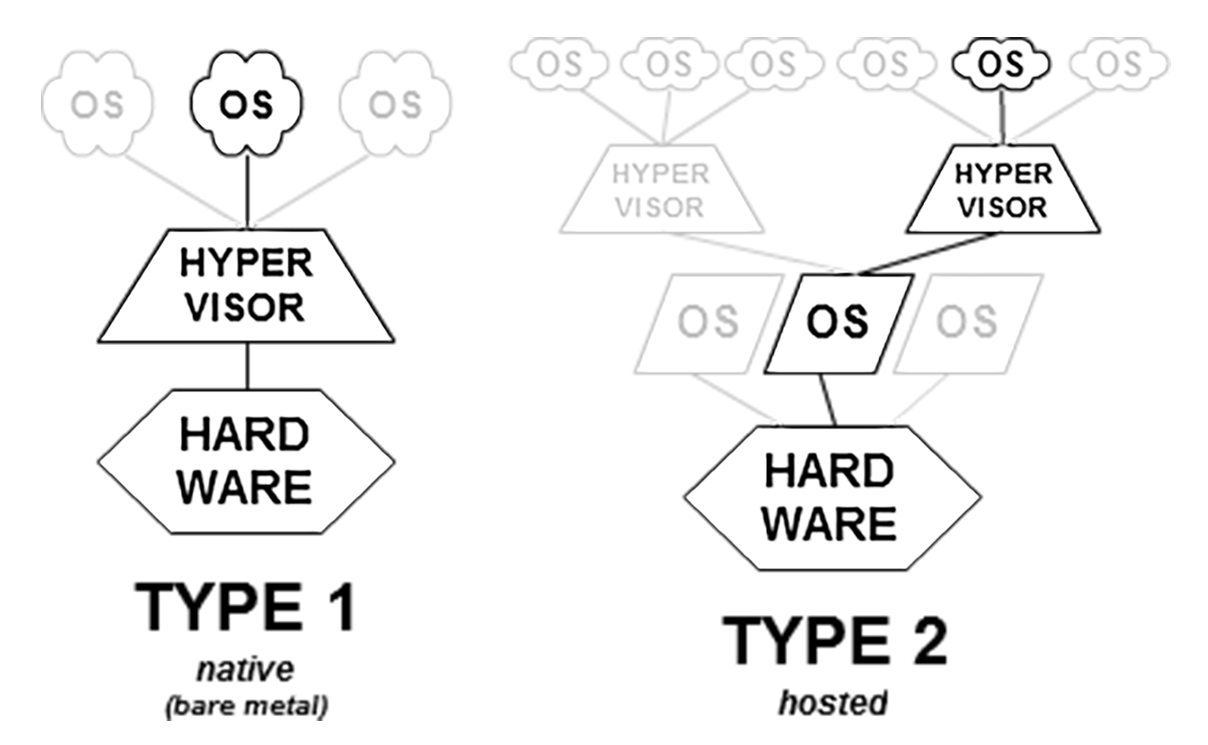 Type 1 and Type 2 Hypervisor, from https://en.wikipedia.org/wiki/Hypervisor
Virtual Box pretends to be a physical machine, it emulates everything: all the hardware, from networking interfaces to graphics, etc. The guest OS thinks it runs on real hardware, so you can install pretty much anything you want, from Ubuntu to Windows, there are virtually no limitations. Except an original MacOS, which is very hard to get installed on Virtual Box, but that's another story.
Type 1 and Type 2 Hypervisor, from https://en.wikipedia.org/wiki/Hypervisor
Virtual Box pretends to be a physical machine, it emulates everything: all the hardware, from networking interfaces to graphics, etc. The guest OS thinks it runs on real hardware, so you can install pretty much anything you want, from Ubuntu to Windows, there are virtually no limitations. Except an original MacOS, which is very hard to get installed on Virtual Box, but that's another story.
If your server runs Ubuntu then it's easy to download an Ubuntu ISO, install it on your Virtual Box and start to configure it the same way as your server. And in theory you should reach dev-prod parity. In theory.
If a company has a dedicated SysOps team, then they maybe use tools to automate the configuration. That are tools like Puppet, Ansible or Chef. Here is a comparison of those tools.
With these tools you would automate everything, from what software to install, how to configure the software, what versions of libraries, etc etc. It can bring you very close to production and make you life very easy, once everything is setup. And if you build out a virtual box image using your configuration, you can easily distribute it across your team members. That's very convenient and a common practice.
Problems using Virtual Machines or Vagrant
There are some problems attached to it. First of all, not everyone wants to spend time learning additional tools like Ansible or Puppet. Not everyone has a dedicated team to make and maintain those virtual box images. So you end up with some sort of intermediate stage where you update your virtual box images maybe once a year ... or every other year ... or every 5 years ... or never.
To make the developer life easier and manage virtual boxes from the command line, a tool called Vagrant came along.
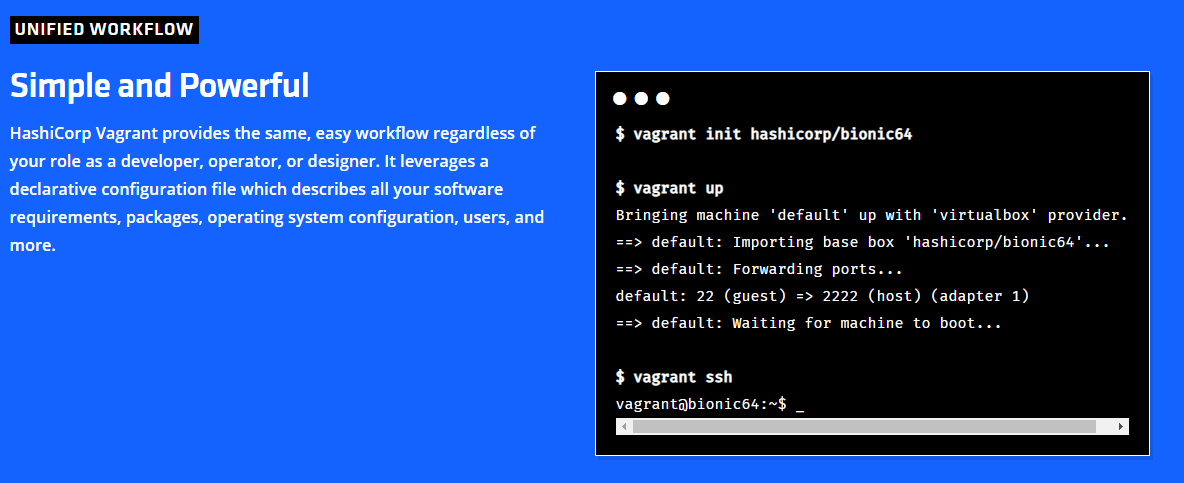 Screenshot of the Vagrant Website. On the right side, you see how easy it is to get started with a virtual machine image.
With Vagrant you don't need to install Ubuntu first, then configure Ubuntu, then install Apache, then configure Apache, then install PHP and then install and configure MySQL. Very much like the MAMP or WAMP, there are pre-configured images. They are so called boxes and available as "turn key" images to download and use right out the box.
Screenshot of the Vagrant Website. On the right side, you see how easy it is to get started with a virtual machine image.
With Vagrant you don't need to install Ubuntu first, then configure Ubuntu, then install Apache, then configure Apache, then install PHP and then install and configure MySQL. Very much like the MAMP or WAMP, there are pre-configured images. They are so called boxes and available as "turn key" images to download and use right out the box.
You can even go one step further, and script the whole download, configuration and provisioning step. That's where a so-called "Vagrantfile" comes in. You would create a so called "Vagrantfile" text-file, define which base-box it would use, define networking, maybe map a directory into the box and also define a provisioning script when the box first starts. Done.
Vagrant.configure("2") do |config|
config.vm.box = "scotch/box"
config.vm.hostname = "my.box"
config.vm.network :private_network, ip: "192.168.100.42"
end
Example of a "Vagrantfile"
That way you can easily ship this file together with your GitHub repository. When someone downloads the repository, all he has to enter is vagrant up and it would download the right box, provision everything and done. In theory.
While this is a super-simple example, the problem is, those scripts can get very large and complex. And updates are not always so straight forward. There are problems attached to it, which you encounter every day, like permissions or having symbolic links enabled. Also, it doesn't solve the initial problem: using Vagrant, your development environment is again different than your production environment, albeit already better than Windows vs Linux.
Another problem is speed, especially on older Laptops. With a Hypervisor you add another large layer to execute some programs in a separate environment.
On the plus side, you get a robust separation of your host and guest OS and you can be very close to production. The guest OS itself isn't actually much slower, but, because you need another layer of libraries, another kernel running, and just a lot of resources, you will notice a performance decrease.
Configuration Drift and Mutable Servers
One of the biggest problems I found with Virtual Machines is the configuration drift.
What is configuration drift? When you get a new server, or setup something the first time, everything is perfect. Then time passes, requirements change slightly. After a while, maybe people start logging into the server and changing something which isn't in your configuration automation tools. Or a new library gets released and changes something unexpectedly because of an update. Something that can only be achieved by going from version 1 to version 2.
You maybe use Ansible or Puppet, which makes things slightly better, but even there I have seen it. And here you go, your server looks different than a new server you setup.
This is configuration drift. Your current configuration drifts away from your initial configuration. Of course there are tons of approaches to solve this problem, but it all comes down to the fact that your servers are mutable.
That includes virtual machines. They are mutable machines. That means they can change while they are running, like a server or like a Windows changes over time. Remember those Windows 95 days where a fresh install made everything fast again?
If you have a long running server, you occasionally log in, do something like apt-get update && apt-get dist-upgrade in one way or another. Maybe automated. The point is, your server changes. This is where containers with immutable data structure can shine. More on that below.
Benefits of using Virtual Machines and Vagrant
For many people Virtual Machines are the go-to solution to bring development close to production. Also for many applications the small difference between Vagrant boxes and a production environment is neglect-able. In all the years I have used Ansible and my scotch/box or homestead images, I had exactly zero problems because of configuration drift.
It's fast to setup, it is easy to understand, it's a server on your machine. So, on-boarding this technique is fairly straight forward.
You can map your windows-directory *into *your virtual machine, so you can use all your favorite IDEs on Windows and just use the virtual machine to serve the content through Apache or Nginx or use MySQL inside your VM.
If you run your development environment on a laptop, it might become a bit slow. Sometimes things break from one version of Virtual Box to the other. And this was the actual breaking point for me. And then I started using Docker.
So, the next logical step is to strive for clear service separation, but with the performance of a local development environment, which is close to production.
Welcome Containerization!
Containers, Docker or Kubernetes
According to the Oxford dictionary: A container is "an object for holding or transporting something." And this is also somewhat true for Containers in the software world.
A container, from the perspective of a regular developer, isn't so much different than a virtual machine at first. It runs a program (or service), such as Apache, in a separate environment. You can map directories inside a container, very much like with Vagrant or Virtual Box. But underneath is a whole lot different.
Firstly, on a container platform, not all the hardware gets simulated, like using a Hypervisor. The main difference is, a container executes commands on the kernel of the host operating system. That means, it basically runs on the host, but is entirely separated from it. Which is pretty cool.
In the very early days people started to use a tool called chroot to create separate environments on Linux. And then some containerization platforms came up - Docker isn't the only one and definitely not the first one.
- There is RKT, pronounced "Rocket" from CoreOS, which is a large competitor of Docker.
- There is LXC, or "linux containers".
- And there is OpenVZ from Virtuozzo
I think those three are the biggest players and also biggest Docker competitors in the market. So, that makes 4 large players, including Docker.
A container engine not only separates the file system in the guest from the host, but also separates networking, IO access, memory, and provides interfaces for orchestration.
But what's in a container anyways and why is it better than a virtual machine? Remember the graphics before where the App runs on the guest OS runs on top of a Hypervisor on top of a host OS on top of hardware? A classic example: Hardware -> Windows/MacOS -> Virtual Box -> Ubuntu -> Apache.
With a container, you can use the Kernel of the host to run apps as the guest. And everything else inside the guest is separated from the host, including the process id from inside. Your container-image would include all and everything to run the process, like Apache, but would execute it on the host, but in a separated environment.
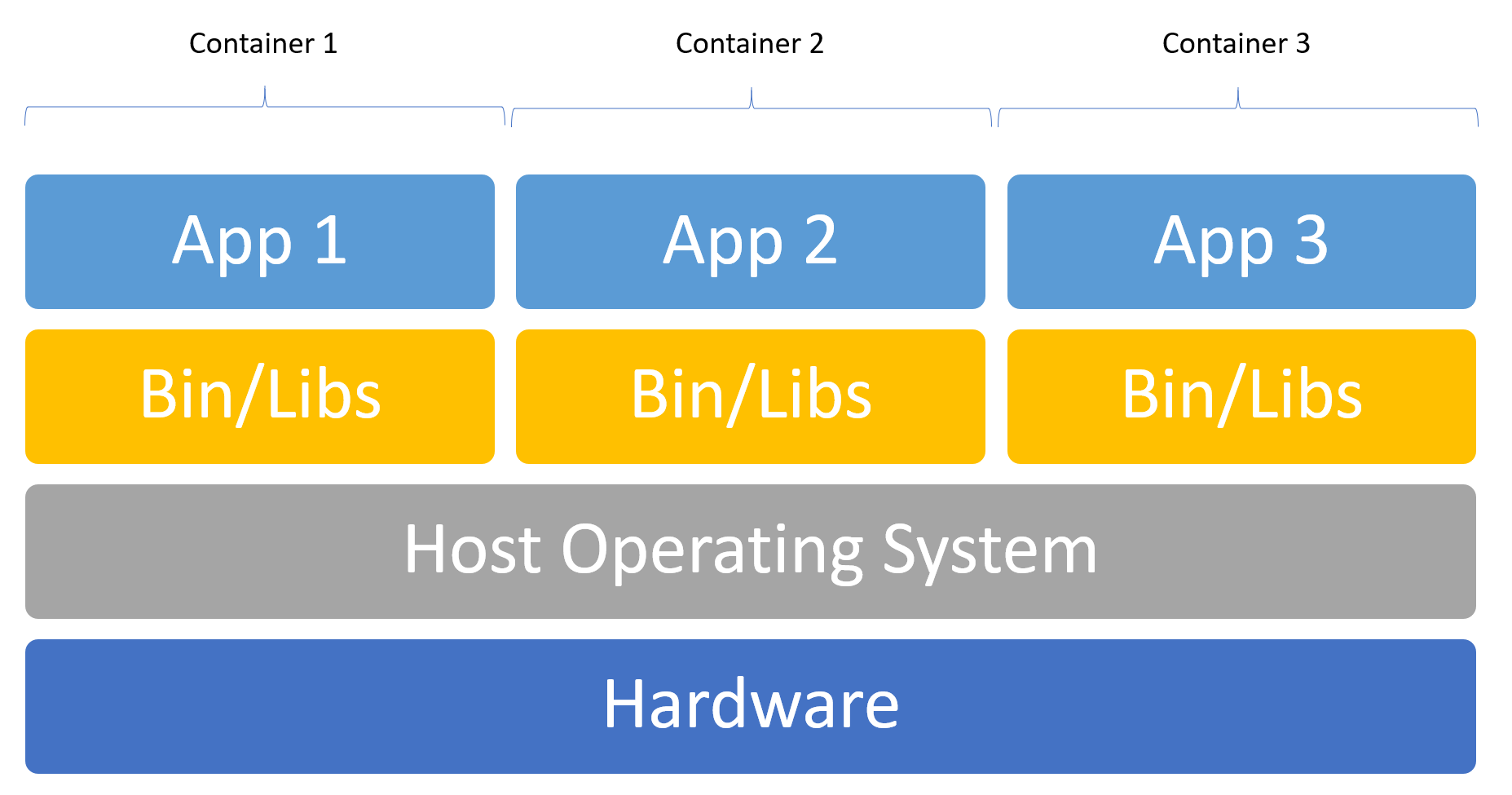 And that is the crucial point: If you want to run an Apache, you would ship the executable and all libraries the Apache needs to run on a linux kernel. Basically everything except the kernel. And the collection of files and configurations is called an image. And that image is then run, so the instance of an image is a container. And a container always has one process running, the process with the ID 1, which is, if you are only running Apache, the webserver. And the container runs as long as the process with ID 1 is running. Then it ends itself. The process can spawn other processes inside the container, but, as far as I know, there can't be a container without a process with PID 1.
And that is the crucial point: If you want to run an Apache, you would ship the executable and all libraries the Apache needs to run on a linux kernel. Basically everything except the kernel. And the collection of files and configurations is called an image. And that image is then run, so the instance of an image is a container. And a container always has one process running, the process with the ID 1, which is, if you are only running Apache, the webserver. And the container runs as long as the process with ID 1 is running. Then it ends itself. The process can spawn other processes inside the container, but, as far as I know, there can't be a container without a process with PID 1.
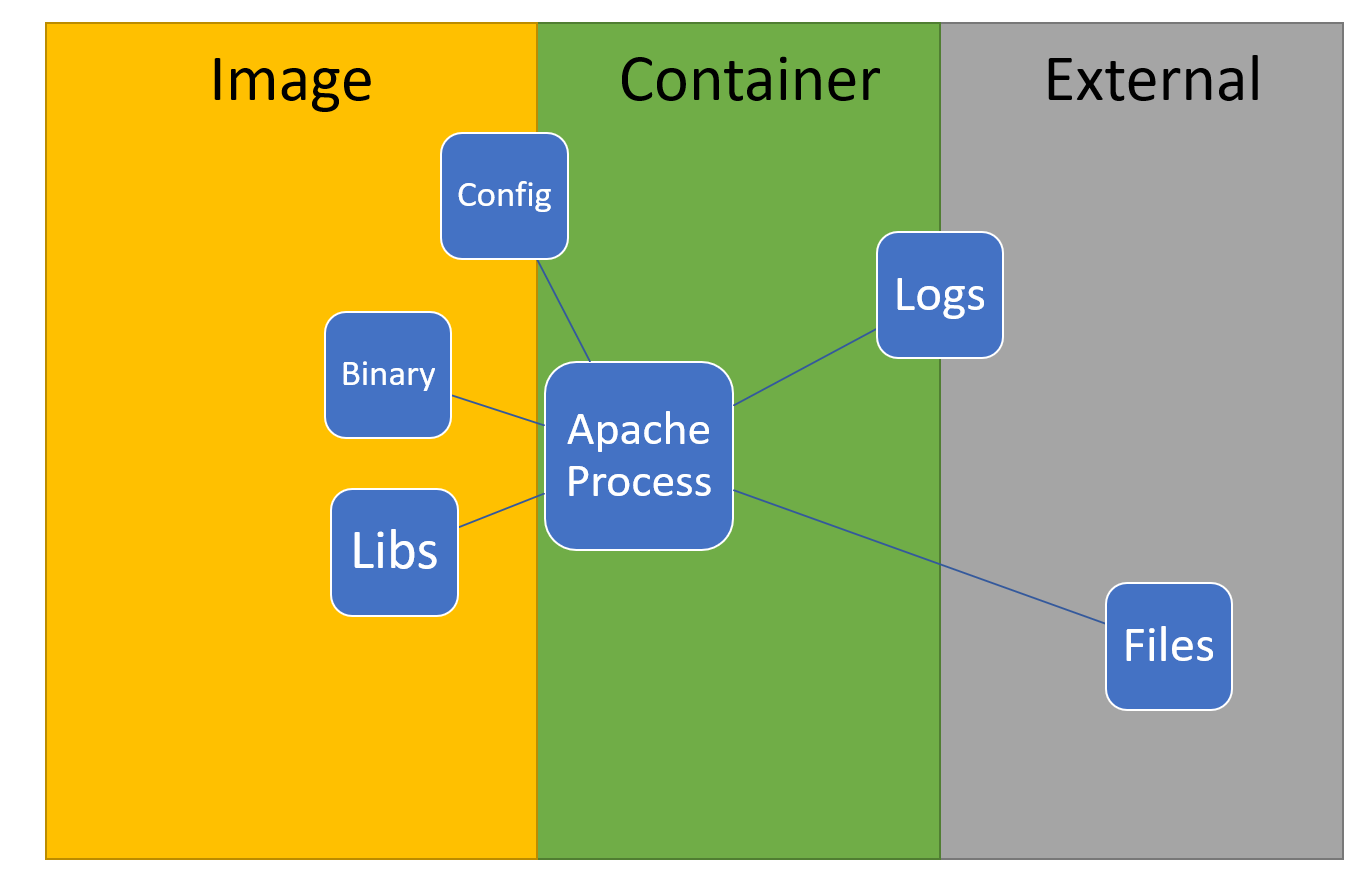 Binary and Library is definitely inside the container, Configs can be mapped into, but most are already provided. Logs and Files are somewhat outside the container, usually.
Then there are files. You can, but you probably would not have your files inside the container. They are separated from the container and are mounted from the outside into the container. You would not have logs in there. You would not have anything in there which changes the container itself. Just the stuff the Apache needs, including libraries and config files. Everything else is outside.
Binary and Library is definitely inside the container, Configs can be mapped into, but most are already provided. Logs and Files are somewhat outside the container, usually.
Then there are files. You can, but you probably would not have your files inside the container. They are separated from the container and are mounted from the outside into the container. You would not have logs in there. You would not have anything in there which changes the container itself. Just the stuff the Apache needs, including libraries and config files. Everything else is outside.
Why is this so important?
By separating data and libraries/binaries, you create an immutable system. For example, if you want to update Apache, you update the image, take the running container down and start a new container with the updated image.
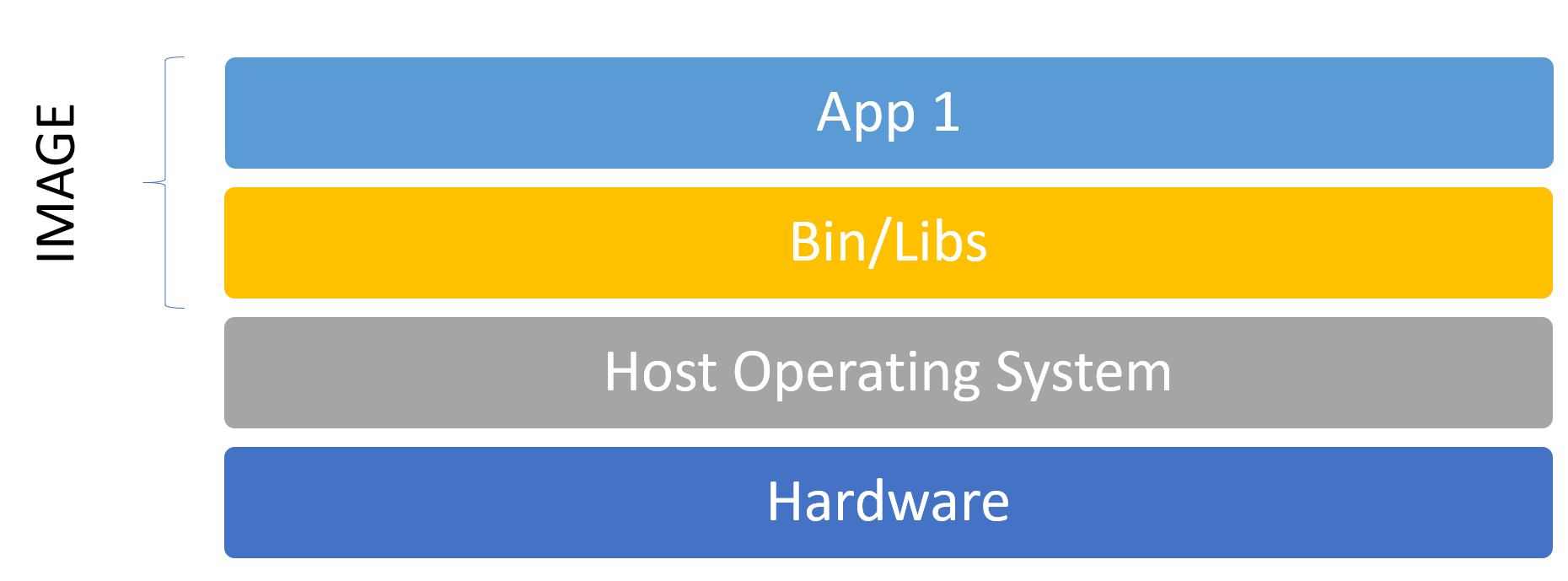 Configuration drift can never occur. Containers are short-running, they are not getting new configs, no updates. If your Apache process ends, your container ends, and may get started again from an image. The images get the updates. The containers should remain immutable.
Configuration drift can never occur. Containers are short-running, they are not getting new configs, no updates. If your Apache process ends, your container ends, and may get started again from an image. The images get the updates. The containers should remain immutable.
Images are easy to ship around. They just have everything in there to run a container. That container can be run on a developer machine, it can be run on a server, in the cloud, it doesn't matter. From the point of view from a container, it doesn't matter where it runs. It just serves its purpose and one purpose only.
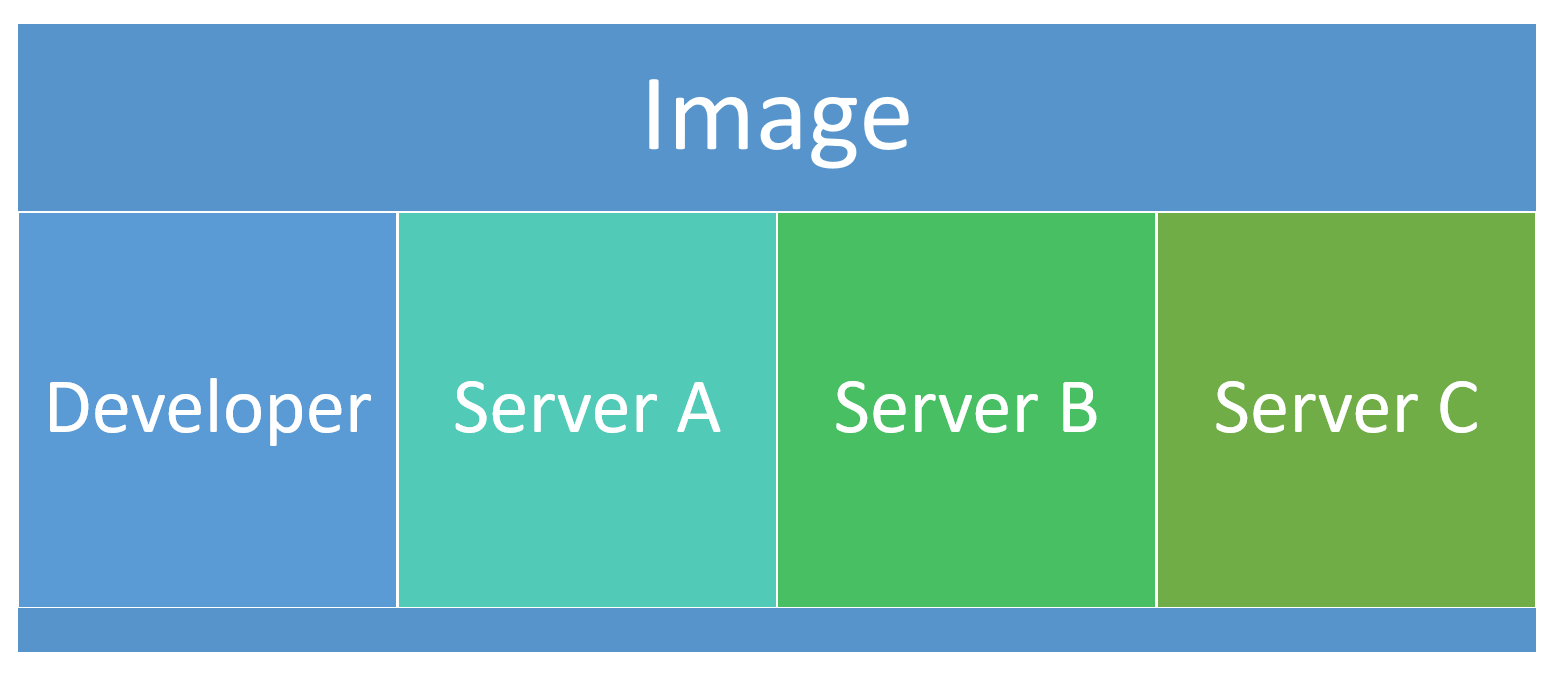 You can install your Container Image really everywhere, it doesn't matter.
That means, if you want an Apache and a MySQL server, you would have two images which are run as two different containers. One with the webserver service and another one with the database service. This concept is important to understand, because with the virtual machine approach, you would probably have one virtual machine containing both Apache and MySQL and possible a lot more services inside.
You can install your Container Image really everywhere, it doesn't matter.
That means, if you want an Apache and a MySQL server, you would have two images which are run as two different containers. One with the webserver service and another one with the database service. This concept is important to understand, because with the virtual machine approach, you would probably have one virtual machine containing both Apache and MySQL and possible a lot more services inside.
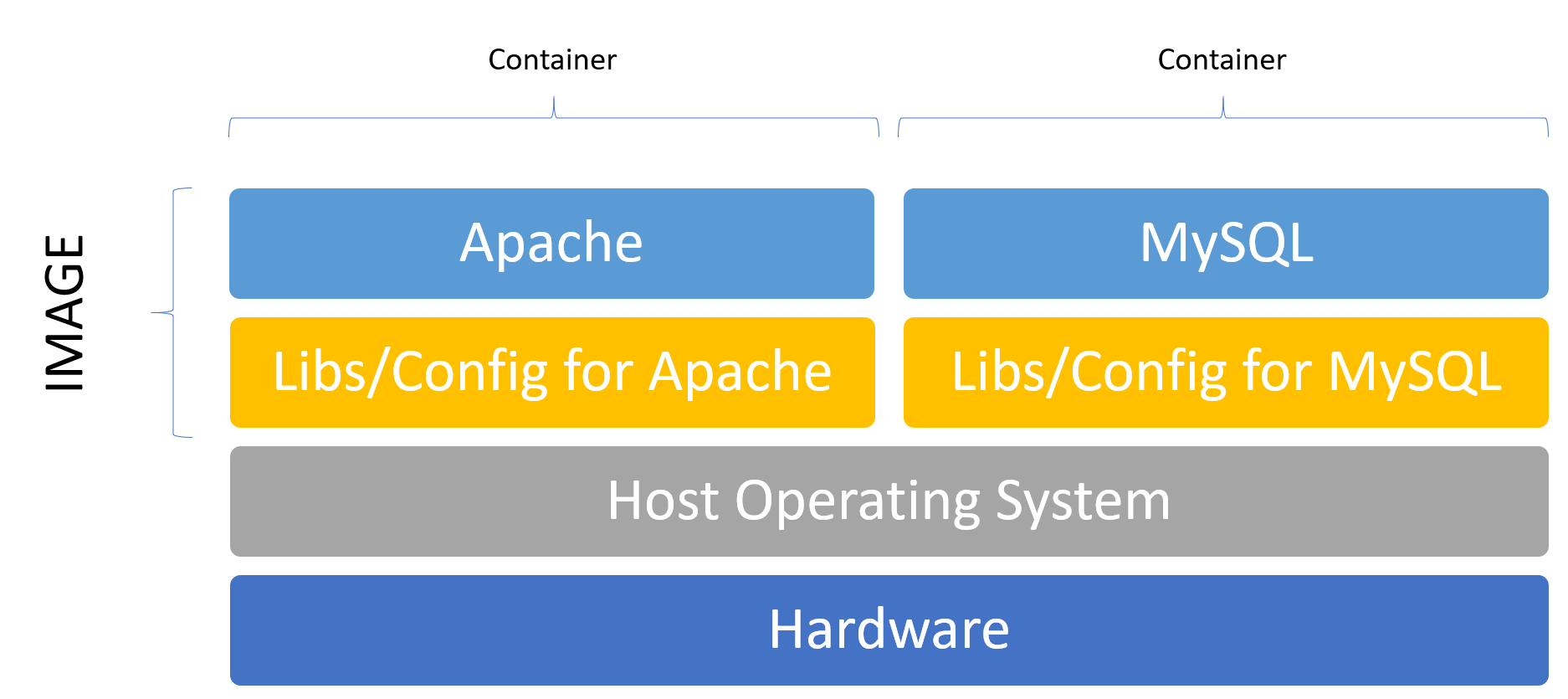 Here Apache would be one image and MySQL would be another image. If they are run, they are containers, the running instances of images.
Here Apache would be one image and MySQL would be another image. If they are run, they are containers, the running instances of images.
Problems using Containers
Compared to a local file system approach, it adds complexity. It's not so easy to understand how things are working and the learning curve is somewhat steeper than with the other two approaches.
It's also not so straight forward how to connect multiple containers, both networking and file-system wise. It's called container orchestration.
Let's take an example of a classical Docker container setup, you'd see in practice every day.
There is the Apache container, running the "WebApp" mentioned before, and the MySQL container, running the Database to persist data. For both services you would most likely setup a Dockerfile, which defines how the images look like.
So, the first step would be to write a Dockerfile:
FROM php:7.3-apache
ENV APACHE_DOCUMENT_ROOT /path/to/new/root
RUN sed -ri -e 's!/var/www/html!${APACHE_DOCUMENT_ROOT}!g' /etc/apache2/sites-available/*.conf
RUN sed -ri -e 's!/var/www/!${APACHE_DOCUMENT_ROOT}!g' /etc/apache2/apache2.conf /etc/apache2/conf-available/*.conf
A very simple example Dockerfile for the Apache Container
2. Then you need to build this image: docker built -t myappcontainer:12 .
-
If you run an image repository, you'd need to push them to the image repository.
-
Then everyone on your team (or on the servers) needs to get the latest image.
-
And start this as containers, something like:
docker run -p 8080:80 -v /some/dir:/path/to/new/root myappcontainer:12. -
Then you also need to start mysql:
docker run --name some-mysql -v /my/own/datadir:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=my-secret-pw -d mysql:
Not quite as straight forward as compared to a simple apt-get update .
If Docker doesn't tell you much at the moment, don't worry, start here to write your first Docker command today: [
Docker Run Tutorial for absolute Beginners: Run a single docker container explained step by step
Are you disappointed by the Docker Getting-Started docs? You couldn’t find anything suitable on YouTube? You want real hands-on? Then get started reading this! Make sure you installed “Docker…
 Thomas WiesnerMedium
Thomas WiesnerMedium
 ](
](Benefits of using Containers over Virtual Machines
Obviously, not everything is bad. Not at all with containers. In fact, I think, once you overcome the initial hurdle with Docker you are much better positioned to get to dev-prod-parity.
With containers you can be fairly confident that *most *things that work in your development environment will also work almost exactly the same as in your production environment. Of course, this holds only true if you use the images in production as well...
Using containers and splitting up services into multiple containers makes it much easier to understand. It's like Lego: You don't like the green one, just take a red one instead. There is no need to completely start from scratch. In a monolithic system, like a virtual machine, you most likely start over with a fresh install of Ubuntu if you don't like your setup.
Docker became the go-to solution for containers in the past few years. It doesn't solve everything well, but it's so easy to learn and so easy to apply that most major software packages release Docker-Images. This can be anything from a simple Apache to a more complicated configuration for the ELK stack or Pimcore even. That means, starting with a pre-configured image that does one thing and one thing only and that well isn't hard anymore. It's easy. In fact, it's so easy that a lot of large corporations are using exactly this and only this.
Orchestration using Docker-Compose and clusters using Swarm or Kubernetes
In the previous example, you were starting two containers, providing two services: A database container (MySQL) and a webserver (PHP + Apache). But somehow, every time you start your development in the morning, it's cumbersome to start all the tools from the command line one by one. Especially if you have a ton more tools, like Redis, Elasticsearch, etc.
Add in that you somehow need to tell your colleagues or other people how to get those services up and running, how to configure them and how they are supposed to work together.
This is where *orchestration *comes in. You basically manage all your services from one single file. This is where docker-compose really shines with a perfect trade-off between simplicity and "good enough for every day use". With docker-compose you would manage your services on your machine, define which service depends on which one, define networks, volumes and many more details so those services work well together.
A typical docker-compose file defines all the services, networks and volumes it needs in one single YAML file called "docker-compose.yml". For example, for WordPress it looks like this:
version: '3.3'
services:
db:
image: mysql:5.7
volumes:
- db_data:/var/lib/mysql
restart: always
environment:
MYSQL_ROOT_PASSWORD: somewordpress
MYSQL_DATABASE: wordpress
MYSQL_USER: wordpress
MYSQL_PASSWORD: wordpress
wordpress:
depends_on:
- db
image: wordpress:latest
ports:
- "8000:80"
restart: always
environment:
WORDPRESS_DB_HOST: db:3306
WORDPRESS_DB_USER: wordpress
WORDPRESS_DB_PASSWORD: wordpress
WORDPRESS_DB_NAME: wordpress
volumes:
db_data: {}
docker-compose.yml file for Wordpress from the official wordpress docs
You see the services? There is a "db", which is a mysql:5.7. Then there is a "wordpress" services, which takes directly an image called "wordpress:latest", and the database is stored in a volume called "db_data". All you need is that docker-compose file and you just need to type in docker-compose up.
But having one single Apache container isn't necessarily going to scale well, if your application is under heavy load. Sometimes you need multiple containers of the same base image. This is where clusters come in.
Once you have all your services defined and neatly separated, it's quite easy to scale up certain parts of your app, both horizontally and vertically. Horizontal scaling means you add more machines (or nodes) to your cluster. Vertical scaling means you make a machine (or node) more powerful.
Depending on the orchestration tool you use, this can be complicated, or, well ... really complicated and complex. There are several tools out there, but I think the most confusing is the difference between docker-compose, docker-swarm and Kubernetes (or K8s).
- Docker, actually the Docker Engine, is the foundation and provides a daemon to run containers
- Docker CLI is a command line tool to talk to the Docker Engine, start, stop containers, or enter containers.
- Docker-Compose is the orchestration tool for quickly spinning up containers on a developers machine.
- Docker-Swarm is a cluster solution from Docker. It allows for horizontal scaling. Docker swarm understands mostly the same commands as all the other tools in Docker and it's fairly simple to understand and deploy.
- Kubernetes is the container-solution developed by Google and I couldn't say it any better than on their website: "Kubernetes is an open-source system for automating deployment, scaling, and management of containerized applications."
Kubernetes is quite more complex than Docker, but also way more powerful. It exceeds the contents of this blog post to dive into the difference between Docker and Kubernetes, but I found another blog post about it, if you are interested.
Summary
All in all, I would love to say there is only one way to solve this dev-prod parity dilemma. It isn't that easy though.
With a local development, you're up and running fairly quickly. If you have just a really small app, do prototyping, then there isn't a need for any additional overhead.
With virtual machines you get a system that's easy to understand and works fairly well for smaller teams as well. It isn't perfect, but it doesn't require to learn anything really.
With containers you get a very flexible system and immutable containers which can also be deployed to production, or across all your team members. It scales well and can also be used in large cluster deployments.
The choice certainly depends on the situation you are in and the knowledge you have.
If you want to know how Docker works today, then join this beginners Docker Course. It's 100% hands-on and at the end you will know how to use Docker, write Dockerfiles and orchestrate your own environment using docker-compose.yml files: [
Understanding Docker and Docker-Compose - Hands-On (2019)
Learn all about Docker, Containers, Images, Dockerfile and Docker-Compose with Practical Hands-On Exercises.
 Udemy
Udemy
 ](https://www.udemy.com/course/docker-and-docker-compose-hands-on-by-example/)
Other than that, I hope you found this article useful. If so, why not share it?
](https://www.udemy.com/course/docker-and-docker-compose-hands-on-by-example/)
Other than that, I hope you found this article useful. If so, why not share it?